Managing Harvests
The main page on the IOOS Harvest Registry site is a dashboard displaying a list of harvest sources currently in the system. A harvest, is a description of a metadata source which includes:
- Name: A self-descriptive name used in the registry to differentiate it from other harvests.
- URL: The URL to the web accessible folder or CSW where the metadata documents are hosted
- Harvest Type: The content type of the URL:
- WAF: Web acessible Folder
- ERDDAP WAF: ERDDAP-hosted web accessible folder
- CSW: Catalog Service for the Web
- Publish Source (check box): Should the contents be copied into CKAN?
- Organization: Who does the data belong to?
When the page initially loads, the dashboard is a table of each harvest registered in the system. Along the top of the dashboard is a heading item that contains the total number of registered harvests in the system.
The table has some basic capabilities for ordering and searching. For example, if I want to see all of the harvests with the word NANOOS in the contents, I can search for NANOOS in the search field.
Each row has several links. There’s a link to the URL in the harvest listed under the URL column. There’s a link to the CKAN page listing the harvest contents that have been successfully registered in CKAN under the CKAN Harvest URL column.
Current List of WAFs - Harvest Registry About Page
A list of the WAFs and associated organizations currently available in the Catalog can be found in the Harvest Registry About Page.
This page also includes dataset counts and datasets with validation errors counts on a harvest source-by-harvest source basis.
Adding a new harvest
Along the top of the harvest dashboard is a button labeled “Add Harvest”. Clicking this button will open a form along the right side of the page.

Note:: Use ‘ERDDAP WAF’ Harvest Type for all ERDDAP WAF sources. The regular ‘WAF’ type will generally work from ERDDAP 1.82 onwards, however occasional issues have been encountered. ERDDAP WAF is known to work for all ERDDAP versions.
If the harvest is set to publish (indicated by the “Publish this source?” check box), once the harvest is submitted a job will be submitted. A worker will download all the contents it can find in the URL to a folder in the central waf under the organization’s folder.
If a harvest is set to publish, once per day it will be downloaded into the the central waf.
Notes about Dataset Age
Any datasets in the the central waf that are older than 24 hours will be deleted. This creates a tighter consistency between what data providers are hosting and what’s available through the IOOS Catalog.
XML Validation
Every time a harvester downloads the contents of a source into the central waf, the contents of each XML file is checked. The XML contents are checked using the XML Schema Definition for ISO-19139 created by NGDC. Any validation errors captured by the schema comparison are listed and documented in the records section.
CKAN’s geospatial engine doesn’t support points very well. To offset this limitation, we make a small transformation on the geometry of datasets that are defined as a point. We translate that point into a small (about 1 m²) bounding box so that CKAN can properly index it.
If the file can not be opened by the XML reader, the file will not be copied and an error will be captured attempting to explain the situation as best as it can.
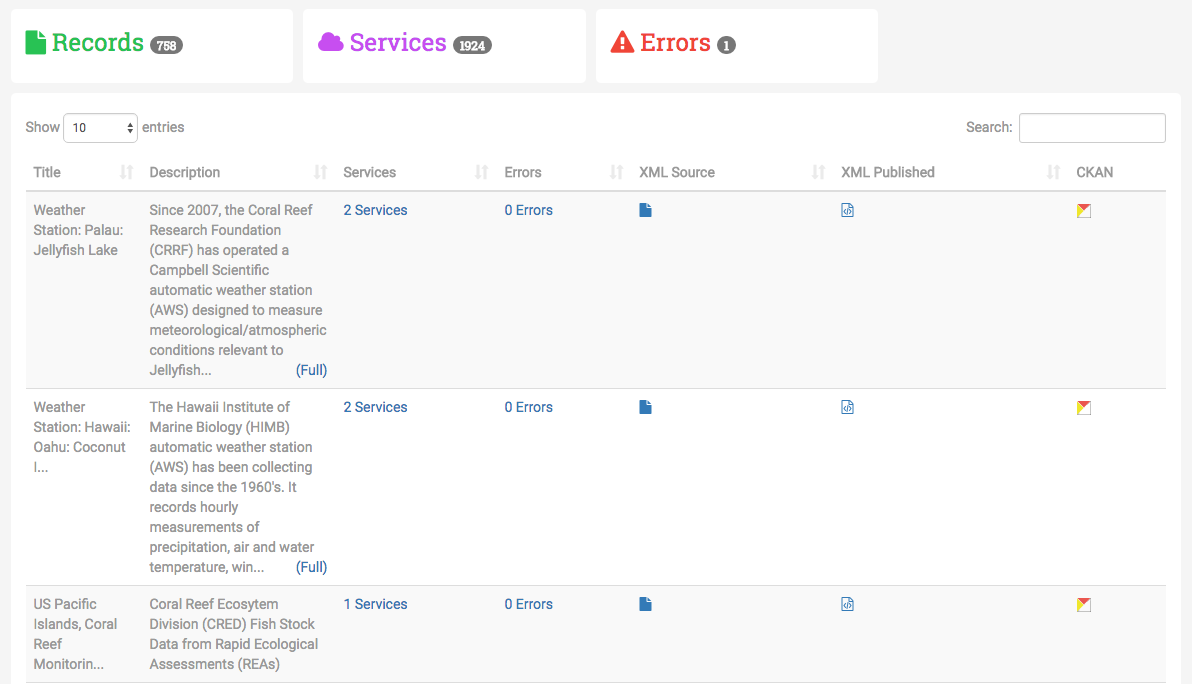
Records Overview
If you click on a row in the table of harvests, a section on the right side of the page populates with information about the harvest. This includes a pie chart displaying the relationship between good records vs bad records. There’s several buttons along the bottom for updating or deleting a harvest.
Clicking either the two records buttons along the dashboard heading or “view records” button along the bottom will take you to the records page for this harvest.
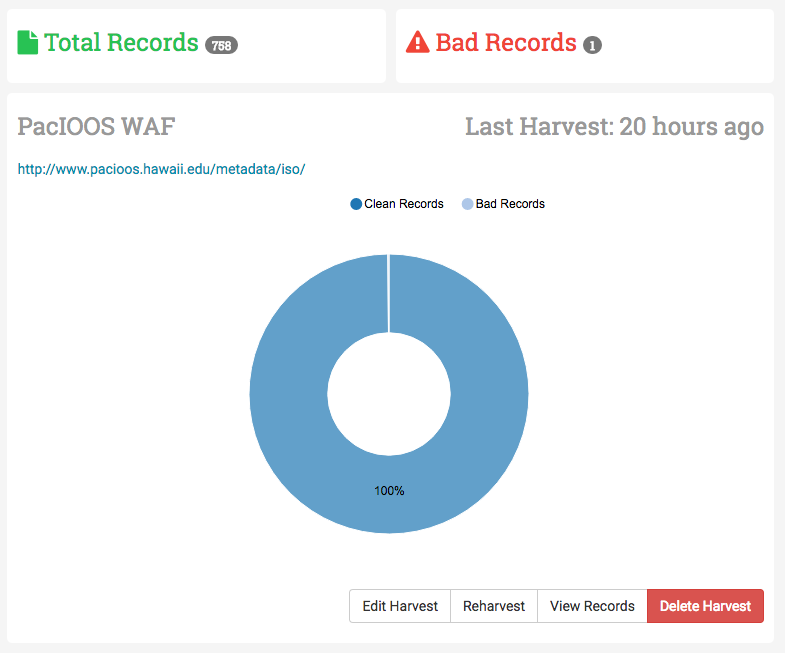
If you click the Bad Records section along the header, you’ll the records page will automatically be sorted by the number of errors per record.
The record page is organized similar to the harvests dashboard. Along the dashboard heading there are three sections. The first section displays the total number of collected from this data source. The second section displays the total number of services offered by the records from this source. The last column displays the total number of errors, whether it’s a parsing error, or validation error.
The table below the heading shows the information relevant to the record to help users identify the individual records. There are three links associated with each record as well. The link under the XML Source column is the URL to the original metadata document hosted by the WAF. The XML Published link points to the URL of the document in the central WAF. The link under the CKAN column is a URL to a search for the document under CKAN. These links are aimed to help users identify issues and verify that the records are being shared correctly.