Using NCEI geoportal REST API to collect information about IOOS Regional Association archived data#
Created: 2017-06-12
Updated: 2024-05-30
IOOS regional associations archive their non-federal observational data with NOAA’s National Center for Environmental Information (NCEI). In this notebook we will use the RESTful services of the NCEI geoportal to collect metadata from the archive packages found in the NCEI archives. The metadata information are stored in ISO 19115-2 xml files which the NCEI geoportal uses for discovery of Archival Information Packages (AIPs). This example uses the ISO metadata records to display publication information as well as plot the time coverage of each AIP at NCEI which meets the search criteria.
First we update the namespaces dictionary from owslib to include the appropriate namespace reference for gmi and gml.
from owslib.iso import namespaces
# Append gmi namespace to namespaces dictionary.
namespaces.update({"gmi": "http://www.isotc211.org/2005/gmi"})
namespaces.update({"gml": "http://www.opengis.net/gml/3.2"})
del namespaces[None]
Now we select a Regional Association and platform#
This is where the user identifies the Regional Association and the platform type they are interested in. Change the RA acronym to the RA of interest. The user can also omit the Regional Association, by using None, to collect metadata information about all IOOS non-Federal observation data archived through the NCEI-IOOS pipeline.
The options for platform include: "HF Radar", "Glider", and "FIXED PLATFORM".
# Select RA, this will be the acronym for the RA or None if you want to search across all RAs
ra = "NANOOS"
# Identify the platform.
platform = (
'"FIXED PLATFORM"' # Options include: None, "HF Radar", "Glider", "FIXED PLATFORM"
)
Next we generate a geoportal query and georss feed#
To find more information about how to compile a geoportal query, have a look at REST API Syntax and the NCEI Search Tips for the NCEI geoportal. The example provided is specific to the NCEI-IOOS data pipeline project and only searches for non-federal timeseries data collected by each Regional Association.
The query developed here can be updated to search for any Archival Information Packages at NCEI, therefore the user should develop the appropriate query using the NCEI Geoportal and update this portion of the code to identify the REST API of interest.
try:
from urllib.parse import quote
except ImportError:
from urllib import quote
# Generate geoportal query and georss feed.
# Base geoportal url.
baseurl = "https://www.ncei.noaa.gov/metadata/geoportal/opensearch?q="
# Identify the Regional Association
if ra is None:
reg_assoc = ""
else:
RAs = {
"AOOS": "Alaska Ocean Observing System",
"CARICOOS": "Caribbean Coastal Ocean Observing System",
"CeNCOOS": "Central and Northern California Ocean Observing System",
"GCOOS": "Gulf of Mexico Coastal Ocean Observing System",
"GLOS": "Great Lakes Observing System",
"MARACOOS": "Mid-Atlantic Regional Association Coastal Ocean Observing System",
"NANOOS": "Northwest Association of Networked Ocean Observing Systems",
"NERACOOS": "Northeastern Regional Association of Coastal Ocean Observing System",
"PacIOOS": "Pacific Islands Ocean Observing System",
"SCCOOS": "Southern California Coastal Ocean Observing System",
"SECOORA": "Southeast Coastal Ocean Observing Regional Association",
}
reg_assoc = (
f'(dataThemeinstitutions_s:"{RAs[ra]}" dataThemeprojects_s:"{RAs[ra]} ({ra})")'
)
# Identify the project.
project = (
'"Integrated Ocean Observing System Data Assembly Centers Data Stewardship Program"'
)
# Identify the amount of records and format of the response: 1 to 1010 records.
records = "&start=1&num=1010"
# Identify the format of the response: georss.
response_format = "&f=csv"
if platform is not None:
reg_assoc_plat = quote(reg_assoc + " AND" + platform)
else:
reg_assoc_plat = quote(reg_assoc)
# Combine the URL.
url = "{}{}{}{}".format(
baseurl,
reg_assoc_plat,
"&filter=dataThemeprojects_s:",
quote(project) + records + response_format,
)
print(f"Identified response format:\n{url}")
print(
"\nSearch page response:\n{}".format(url.replace(response_format, "&f=searchPage"))
)
Identified response format:
https://www.ncei.noaa.gov/metadata/geoportal/opensearch?q=%28dataThemeinstitutions_s%3A%22Northwest%20Association%20of%20Networked%20Ocean%20Observing%20Systems%22%20dataThemeprojects_s%3A%22Northwest%20Association%20of%20Networked%20Ocean%20Observing%20Systems%20%28NANOOS%29%22%29%20AND%22FIXED%20PLATFORM%22&filter=dataThemeprojects_s:%22Integrated%20Ocean%20Observing%20System%20Data%20Assembly%20Centers%20Data%20Stewardship%20Program%22&start=1&num=1010&f=csv
Search page response:
https://www.ncei.noaa.gov/metadata/geoportal/opensearch?q=%28dataThemeinstitutions_s%3A%22Northwest%20Association%20of%20Networked%20Ocean%20Observing%20Systems%22%20dataThemeprojects_s%3A%22Northwest%20Association%20of%20Networked%20Ocean%20Observing%20Systems%20%28NANOOS%29%22%29%20AND%22FIXED%20PLATFORM%22&filter=dataThemeprojects_s:%22Integrated%20Ocean%20Observing%20System%20Data%20Assembly%20Centers%20Data%20Stewardship%20Program%22&start=1&num=1010&f=searchPage
Time to query the portal and parse out the csv response#
Here we are opening the specified REST API and parsing it into a string. Then, since we identified it as a csv format above, we parse it using the Pandas package. We also split the Data_Date_Range column into two columns, data_start_date and data_end_date to have that useful information available.
import numpy as np
import pandas as pd
df = pd.read_csv(url)
df[["data_start_date", "data_end_date"]] = df["Data_Date_Range"].str.split(
" to ", expand=True
)
df["data_start_date"] = pd.to_datetime(df["data_start_date"])
df["data_end_date"] = pd.to_datetime(
df["data_end_date"], errors="coerce"
) + pd.Timedelta(np.timedelta64(1, "ms"))
# Some cleanups
df = df.dropna(axis=1, how="all").dropna()
df.head()
| Id | Title | West | South | East | North | Link_Xml | Data_Date_Range | Date_Published | data_start_date | data_end_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gov.noaa.nodc:0162194 | Oceanographic data collected from Hammond Tide... | -123.95167 | 46.20267 | -123.95167 | 46.20267 | http://www.ncei.noaa.gov/metadata/geoportal/re... | 2005-06-24T00:00:00Z to 2013-02-08T23:59:59.999Z | 2017-03-21T00:00:00Z | 2005-06-24 00:00:00+00:00 | 2013-02-09 00:00:00+00:00 |
| 1 | gov.noaa.nodc:0162195 | Oceanographic data collected from SATURN River... | -123.87195 | 46.23498 | -123.87195 | 46.23498 | http://www.ncei.noaa.gov/metadata/geoportal/re... | 2009-06-06T00:00:00Z to 2010-10-22T23:59:59.999Z | 2017-03-21T00:00:00Z | 2009-06-06 00:00:00+00:00 | 2010-10-23 00:00:00+00:00 |
| 2 | gov.noaa.nodc:0162176 | Oceanographic data collected from Jetty A by C... | -124.03168 | 46.26712 | -124.03168 | 46.26712 | http://www.ncei.noaa.gov/metadata/geoportal/re... | 2003-07-20T00:00:00Z to 2016-02-04T23:59:59.999Z | 2017-03-20T00:00:00Z | 2003-07-20 00:00:00+00:00 | 2016-02-05 00:00:00+00:00 |
| 3 | gov.noaa.nodc:0162190 | Oceanographic data collected from Tenasillahe ... | -123.46828 | 46.23763 | -123.46828 | 46.23763 | http://www.ncei.noaa.gov/metadata/geoportal/re... | 2004-01-23T00:00:00Z to 2011-11-17T23:59:59.999Z | 2017-03-20T00:00:00Z | 2004-01-23 00:00:00+00:00 | 2011-11-18 00:00:00+00:00 |
| 4 | gov.noaa.nodc:0162191 | Oceanographic data collected from Woody Island... | -123.53420 | 46.25212 | -123.53420 | 46.25212 | http://www.ncei.noaa.gov/metadata/geoportal/re... | 1997-02-07T00:00:00Z to 2021-09-01T23:59:59.999Z | 2017-03-20T00:00:00Z | 1997-02-07 00:00:00+00:00 | 2021-09-02 00:00:00+00:00 |
Now, lets pull out all the ISO metadata record links and print them out so the user can browse to the metadata record and look for what items they might be interested in.
# parse the csv response
print(f"Found {len(df)} record(s)")
for index, row in df.iterrows():
print("ISO19115-2 record:", row["Link_Xml"]) # URL to ISO19115-2 record.
print(
"NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id="
+ row["Id"]
)
print("\n")
Found 31 record(s)
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162194/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162194
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162195/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162195
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162176/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162176
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162190/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162190
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162191/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162191
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162179/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162179
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162174/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162174
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0161524/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0161524
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162171/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162171
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162172/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162172
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0161716/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0161716
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0161822/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0161822
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162187/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162187
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162188/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162188
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162189/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162189
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162175/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162175
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162177/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162177
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162181/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162181
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162180/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162180
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162430/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162430
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162178/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162178
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162185/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162185
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162184/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162184
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162622/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162622
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162173/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162173
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162186/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162186
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0167435/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0167435
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162182/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162182
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162621/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162621
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162183/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162183
ISO19115-2 record: http://www.ncei.noaa.gov/metadata/geoportal/rest/metadata/item/gov.noaa.nodc%3A0162617/xml
NCEI dataset metadata page: https://www.ncei.noaa.gov/access/metadata/landing-page/bin/iso?id=gov.noaa.nodc:0162617
Let’s collect what we have found#
Now that we have all the ISO metadata records we are interested in, it’s time to do something fun with them. In this example we want to generate a timeseries plot of the data coverage for the “Southern California Coastal Ocean Observing System” stations we have archived at NCEI.
First we need to collect some information. We loop through each iso record to collect metadata information about each package. The example here shows how to collect the following items:
NCEI Archival Information Package (AIP) Accession ID (7-digit Accession Number)
The first date the archive package was published.
The platform code identified from the provider.
The version number and date it was published.
The current AIP size, in MB.
There are plenty of other metadata elements to collect from the ISO records, so we recommend browsing to one of the records and having a look at the items of interest to your community.
# Process each iso record.
%matplotlib inline
import urllib.error
import xml.etree.ElementTree as ET
from urllib.request import urlopen
import stamina
from owslib import util
@stamina.retry(on=urllib.error.HTTPError, attempts=3)
def openurl(url):
"""Thin wrapper around urlopen adding stamina."""
return urlopen(url)
df[
[
"provider_platform_name",
"NCEI_accession_number",
"package_size_mb",
"submitter",
"version_info",
]
] = ""
# For each accession in response.
for url in df["Link_Xml"]:
iso = openurl(url)
iso_tree = ET.parse(iso)
root = iso_tree.getroot()
vers_dict = dict()
# Collect Publication date information.
date_path = (
".//"
"gmd:identificationInfo/"
"gmd:MD_DataIdentification/"
"gmd:citation/"
"gmd:CI_Citation/"
"gmd:date/"
"gmd:CI_Date/"
"gmd:date/gco:Date"
)
# First published date.
pubdate = root.find(date_path, namespaces)
print(f"\nFirst published date = {util.testXMLValue(pubdate)}")
# Data Temporal Coverage.
temporal_extent_path = (
".//"
"gmd:temporalElement/"
"gmd:EX_TemporalExtent/"
"gmd:extent/"
"gml:TimePeriod"
)
beginPosition = root.find(
temporal_extent_path + "/gml:beginPosition", namespaces
).text
endPosition = root.find(temporal_extent_path + "/gml:endPosition", namespaces).text
print(f"Data time coverage: {beginPosition} to {endPosition}")
# Collect keyword terms of interest.
for MD_keywords in root.iterfind(
".//gmd:descriptiveKeywords/gmd:MD_Keywords", namespaces
):
for thesaurus_name in MD_keywords.iterfind(
".//gmd:thesaurusName/gmd:CI_Citation/gmd:title/gco:CharacterString",
namespaces,
):
if thesaurus_name.text == "Provider Platform Names":
plat_name = MD_keywords.find(
".//gmd:keyword/gco:CharacterString", namespaces
).text
print(f"Provider Platform Code = {plat_name}")
df.loc[df["Link_Xml"] == url, ["provider_platform_name"]] = plat_name
break
elif thesaurus_name.text == "NCEI ACCESSION NUMBER":
acce_no = MD_keywords.find(".//gmd:keyword/gmx:Anchor", namespaces).text
print("Accession:", acce_no)
df.loc[df["Link_Xml"] == url, ["NCEI_accession_number"]] = acce_no
break
elif thesaurus_name.text == "NODC SUBMITTING INSTITUTION NAMES THESAURUS":
submitter = MD_keywords.find(
".//gmd:keyword/gmx:Anchor", namespaces
).text
print("Submitter:", submitter)
df.loc[df["Link_Xml"] == url, ["submitter"]] = submitter
# Pull out the version information.
# Iterate through each processing step which is an NCEI version.
for process_step in root.iterfind(".//gmd:processStep", namespaces):
# Only parse gco:DateTime and gmd:title/gco:CharacterString.
vers_title = (
".//"
"gmi:LE_ProcessStep/"
"gmi:output/"
"gmi:LE_Source/"
"gmd:sourceCitation/"
"gmd:CI_Citation/"
"gmd:title/"
"gco:CharacterString"
)
vers_date = ".//" "gmi:LE_ProcessStep/" "gmd:dateTime/" "gco:DateTime"
if process_step.findall(vers_date, namespaces) and process_step.findall(
vers_title, namespaces
):
# Extract dateTime for each version.
datetime = pd.to_datetime(process_step.find(vers_date, namespaces).text)
# Extract version number.
version = process_step.find(vers_title, namespaces).text.split(" ")[-1]
print(f"{version} = {datetime}")
vers_dict[version] = datetime
df.loc[df["Link_Xml"] == url, ["version_info"]] = [vers_dict]
# Collect package size information.
# Iterate through transfer size nodes.
for trans_size in root.iterfind(".//gmd:transferSize", namespaces):
if trans_size.find(".//gco:Real", namespaces).text:
sizes = trans_size.find(".//gco:Real", namespaces).text
print(f"Current AIP Size = {sizes} MB")
df.loc[df["Link_Xml"] == url, ["package_size_mb"]] = sizes
break
break
First published date = 2017-03-21
Data time coverage: 2005-06-24 to 2013-02-08
Accession: 0162194
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-21 15:34:14+00:00
Current AIP Size = 51.24 MB
First published date = 2017-03-21
Data time coverage: 2009-06-06 to 2010-10-22
Accession: 0162195
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-21 15:35:07+00:00
Current AIP Size = 0.956 MB
First published date = 2017-03-20
Data time coverage: 2003-07-20 to 2016-02-04
Accession: 0162176
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:18:18+00:00
Current AIP Size = 67.96 MB
First published date = 2017-03-20
Data time coverage: 2004-01-23 to 2011-11-17
Accession: 0162190
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:30:14+00:00
Current AIP Size = 22.624 MB
First published date = 2017-03-20
Data time coverage: 1997-02-07 to 2021-09-01
Accession: 0162191
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = Woody Island (USCG Pillar Rock back range board)
v1.1 = 2017-03-20 23:30:25+00:00
v2.2 = 2017-10-17 10:30:16+00:00
v3.3 = 2019-04-18 14:24:02+00:00
v4.4 = 2020-04-18 11:32:05+00:00
v5.5 = 2020-05-18 11:43:45+00:00
v6.6 = 2020-06-18 11:50:15+00:00
v7.7 = 2020-07-18 11:49:00+00:00
v8.8 = 2020-08-18 11:55:02+00:00
v9.9 = 2020-09-22 21:56:53+00:00
v10.10 = 2020-12-18 17:13:11+00:00
v11.11 = 2021-02-22 10:57:10+00:00
v12.12 = 2021-03-20 10:20:36+00:00
v13.13 = 2021-04-18 10:50:23+00:00
v14.14 = 2021-05-19 10:20:35+00:00
v15.15 = 2021-07-21 10:25:39+00:00
v16.16 = 2021-08-21 10:21:45+00:00
v17.17 = 2021-09-20 10:20:37+00:00
Current AIP Size = 43.548 MB
First published date = 2017-03-20
Data time coverage: 2005-01-13 to 2015-10-16
Accession: 0162179
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:19:12+00:00
Current AIP Size = 18.748 MB
First published date = 2017-03-20
Data time coverage: 2004-01-16 to 2021-07-30
Accession: 0162174
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = Elliott Point
v1.1 = 2017-03-20 23:17:26+00:00
v2.2 = 2017-08-16 10:16:10+00:00
v3.3 = 2017-10-16 10:16:07+00:00
v4.4 = 2017-11-16 10:16:08+00:00
v5.5 = 2017-12-16 10:16:10+00:00
v6.6 = 2018-01-16 10:16:09+00:00
v7.7 = 2018-02-16 10:16:09+00:00
v8.8 = 2018-04-16 20:18:11+00:00
v9.9 = 2018-05-17 10:16:11+00:00
v10.10 = 2018-06-17 10:16:13+00:00
v11.11 = 2018-07-17 10:16:14+00:00
v12.12 = 2018-08-17 10:21:11+00:00
v13.13 = 2018-09-17 10:16:12+00:00
v14.14 = 2018-10-17 10:16:13+00:00
v15.15 = 2018-11-17 10:26:15+00:00
v16.16 = 2018-12-17 13:52:40+00:00
v17.17 = 2019-01-17 10:16:43+00:00
v18.18 = 2019-02-17 11:29:14+00:00
v19.19 = 2019-03-21 04:04:28+00:00
v20.20 = 2019-04-17 10:42:42+00:00
v21.21 = 2019-05-17 15:13:46+00:00
v22.22 = 2019-06-17 10:19:10+00:00
v23.23 = 2019-07-17 10:16:44+00:00
v24.24 = 2019-08-17 10:16:53+00:00
v25.25 = 2019-09-17 10:16:45+00:00
v26.26 = 2019-10-17 17:24:04+00:00
v27.27 = 2019-11-17 11:11:34+00:00
v28.28 = 2019-12-17 14:55:46+00:00
v29.29 = 2020-01-18 15:12:10+00:00
v30.30 = 2020-03-16 11:52:43+00:00
v31.31 = 2020-04-17 10:20:01+00:00
v32.32 = 2020-05-17 15:18:00+00:00
v33.33 = 2020-06-17 17:24:37+00:00
v34.34 = 2020-07-17 10:21:54+00:00
v35.35 = 2020-08-17 12:20:10+00:00
v36.36 = 2020-09-22 12:23:20+00:00
v37.37 = 2020-10-17 12:24:19+00:00
v38.38 = 2020-11-17 18:14:59+00:00
v39.39 = 2020-12-17 15:35:51+00:00
v40.40 = 2021-02-17 23:21:45+00:00
v41.41 = 2021-03-17 11:40:02+00:00
v42.42 = 2021-04-17 10:18:40+00:00
v43.43 = 2021-05-17 10:18:38+00:00
v44.44 = 2021-07-18 14:37:42+00:00
v45.45 = 2021-08-18 10:19:49+00:00
Current AIP Size = 32.432 MB
stamina.retry_scheduled
First published date = 2017-03-09
Data time coverage: 2005-12-15 to 2006-04-18
Accession: 0161524
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-09 20:44:09+00:00
Current AIP Size = 1.116 MB
First published date = 2017-03-20
Data time coverage: 2004-01-16 to 2004-12-15
Accession: 0162171
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:14:07+00:00
Current AIP Size = 2.688 MB
stamina.retry_scheduled
First published date = 2017-03-20
Data time coverage: 2003-01-01 to 2013-08-16
Accession: 0162172
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:16:20+00:00
Current AIP Size = 94.676 MB
stamina.retry_scheduled
First published date = 2017-03-14
Data time coverage: 1998-03-01 to 2010-09-22
Accession: 0161716
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-14 11:25:31+00:00
Current AIP Size = 156.028 MB
stamina.retry_scheduled
First published date = 2017-03-15
Data time coverage: 2000-07-02 to 2019-05-30
Accession: 0161822
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-15 16:31:48+00:00
v2.2 = 2019-06-17 10:18:28+00:00
Current AIP Size = 102.536 MB
First published date = 2017-03-20
Data time coverage: 2004-02-03 to 2008-03-19
Accession: 0162187
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:29:39+00:00
v1.2 = 2017-04-04 17:13:06+00:00
v2.3 = 2017-05-12 21:52:07+00:00
Current AIP Size = 11.212 MB
First published date = 2017-03-20
Data time coverage: 2004-01-16 to 2005-08-15
Accession: 0162188
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:29:42+00:00
v1.2 = 2017-04-04 17:13:09+00:00
v2.3 = 2017-05-19 11:26:08+00:00
Current AIP Size = 26.576 MB
First published date = 2017-03-20
Data time coverage: 1996-09-05 to 2014-10-01
Accession: 0162189
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:30:07+00:00
Current AIP Size = 155.688 MB
First published date = 2017-03-20
Data time coverage: 1998-09-03 to 2015-03-26
Accession: 0162175
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:17:43+00:00
Current AIP Size = 84.18 MB
First published date = 2017-03-20
Data time coverage: 2001-09-17 to 2006-10-12
Accession: 0162177
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:18:25+00:00
Current AIP Size = 21.648 MB
First published date = 2017-03-20
Data time coverage: 1997-07-12 to 2014-01-15
Accession: 0162181
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:20:24+00:00
Current AIP Size = 89.492 MB
First published date = 2017-03-20
Data time coverage: 1997-12-02 to 2007-09-17
Accession: 0162180
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:19:46+00:00
Current AIP Size = 214.384 MB
First published date = 2017-04-25
Data time coverage: 2009-06-23 to 2020-12-23
Accession: 0162430
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = SATURN River Station 05
v1.1 = 2017-04-25 00:22:09+00:00
v2.2 = 2017-12-17 07:32:30+00:00
v3.3 = 2018-01-17 07:29:09+00:00
v4.4 = 2018-02-17 07:31:33+00:00
v5.5 = 2018-04-17 10:30:25+00:00
v6.6 = 2018-05-18 10:30:06+00:00
v7.7 = 2018-06-18 10:34:43+00:00
v8.8 = 2018-07-18 10:37:42+00:00
v9.9 = 2018-08-18 10:36:14+00:00
v10.10 = 2018-09-18 10:36:11+00:00
v11.11 = 2018-10-18 10:36:13+00:00
v12.12 = 2018-11-18 11:53:25+00:00
v13.13 = 2018-12-18 15:17:41+00:00
v14.14 = 2019-01-18 10:51:33+00:00
v15.15 = 2019-02-18 10:51:40+00:00
v16.16 = 2019-03-19 10:54:44+00:00
v17.17 = 2019-04-18 14:18:23+00:00
v18.18 = 2019-05-18 10:58:44+00:00
v19.19 = 2019-06-18 12:34:18+00:00
v20.20 = 2019-07-18 10:55:15+00:00
v21.21 = 2019-08-18 11:06:37+00:00
v22.22 = 2019-12-18 10:17:52+00:00
v23.23 = 2020-03-18 10:47:09+00:00
v24.24 = 2020-04-18 11:30:53+00:00
v25.25 = 2020-05-18 11:40:46+00:00
v26.26 = 2020-06-18 11:43:52+00:00
v27.27 = 2020-07-18 11:45:56+00:00
v28.28 = 2020-08-18 11:48:09+00:00
v29.29 = 2020-09-22 21:53:25+00:00
v30.30 = 2020-11-19 09:18:34+00:00
v31.31 = 2020-12-18 17:11:30+00:00
v32.32 = 2021-02-18 12:21:49+00:00
Current AIP Size = 31.932 MB
First published date = 2017-03-20
Data time coverage: 2012-04-28 to 2012-05-17
Accession: 0162178
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:18:28+00:00
Current AIP Size = 0.816 MB
First published date = 2017-03-20
Data time coverage: 2014-09-08 to 2023-11-01
Accession: 0162185
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = SATURN-09
v1.1 = 2017-03-20 23:29:28+00:00
v2.2 = 2017-08-04 11:53:37+00:00
v3.3 = 2019-05-18 11:04:36+00:00
v4.4 = 2019-06-18 12:40:02+00:00
v5.5 = 2019-07-18 10:57:38+00:00
v6.6 = 2019-08-18 11:08:03+00:00
v7.7 = 2019-12-18 10:30:19+00:00
v8.8 = 2020-03-16 13:05:36+00:00
v9.9 = 2020-06-18 11:47:17+00:00
v10.10 = 2020-08-18 11:51:53+00:00
v11.11 = 2021-02-22 10:56:38+00:00
v12.12 = 2021-03-20 10:19:12+00:00
v13.13 = 2021-04-18 10:49:51+00:00
v14.14 = 2021-05-19 10:19:12+00:00
v15.15 = 2021-07-21 10:24:49+00:00
v16.16 = 2021-08-21 10:19:55+00:00
v17.17 = 2021-09-20 10:19:07+00:00
v18.18 = 2023-01-19 10:31:31+00:00
v19.19 = 2023-06-18 11:29:34+00:00
v20.20 = 2023-08-17 12:32:13+00:00
v21.21 = 2023-09-19 15:03:38+00:00
v22.22 = 2023-10-20 11:58:08+00:00
v23.23 = 2023-11-19 10:44:59+00:00
Current AIP Size = 175.38 MB
First published date = 2017-03-20
Data time coverage: 2012-05-03 to 2023-10-05
Accession: 0162184
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = SATURN-07
v1.1 = 2017-03-20 23:29:20+00:00
v2.2 = 2017-08-04 11:53:27+00:00
v3.3 = 2018-05-18 10:30:30+00:00
v4.4 = 2018-06-18 10:35:39+00:00
v5.5 = 2018-07-18 10:38:31+00:00
v6.6 = 2018-08-18 10:36:47+00:00
v7.7 = 2018-09-18 10:37:22+00:00
v8.8 = 2018-10-18 10:37:33+00:00
v9.9 = 2018-11-18 11:56:58+00:00
v10.10 = 2018-12-18 15:21:03+00:00
v11.11 = 2019-01-18 10:55:14+00:00
v12.12 = 2019-02-18 10:55:24+00:00
v13.13 = 2019-03-19 10:58:29+00:00
v14.14 = 2019-04-18 14:22:16+00:00
v15.15 = 2019-05-18 11:02:57+00:00
v16.16 = 2019-06-18 12:38:20+00:00
v17.17 = 2019-12-18 10:28:20+00:00
v18.18 = 2021-03-19 11:20:38+00:00
v19.19 = 2021-05-18 10:47:00+00:00
v20.20 = 2021-07-21 10:23:10+00:00
v21.21 = 2021-08-20 10:55:37+00:00
v22.22 = 2021-09-19 10:50:05+00:00
v23.23 = 2023-01-18 11:26:53+00:00
v24.24 = 2023-02-18 11:10:47+00:00
v25.25 = 2023-03-18 10:55:35+00:00
v26.26 = 2023-04-18 11:18:18+00:00
v27.27 = 2023-05-19 12:11:14+00:00
v28.28 = 2023-06-18 11:26:28+00:00
v29.29 = 2023-07-18 14:41:09+00:00
v30.30 = 2023-08-19 11:17:31+00:00
v31.31 = 2023-09-18 16:55:42+00:00
v32.32 = 2023-10-19 12:28:12+00:00
v33.33 = 2023-11-18 11:13:08+00:00
Current AIP Size = 764.656 MB
First published date = 2017-05-16
Data time coverage: 2012-09-04 to 2019-06-14
Accession: 0162622
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-05-16 14:01:12+00:00
v2.2 = 2017-08-04 11:52:07+00:00
v3.3 = 2017-08-17 08:43:23+00:00
v4.4 = 2017-10-17 10:29:13+00:00
v5.5 = 2018-04-17 10:30:32+00:00
v6.6 = 2018-05-18 10:31:09+00:00
v7.7 = 2018-06-18 10:35:50+00:00
v8.8 = 2018-07-18 10:38:39+00:00
v9.9 = 2018-08-18 10:36:57+00:00
v10.10 = 2018-09-18 10:37:30+00:00
v11.11 = 2018-10-18 10:37:42+00:00
v12.12 = 2018-11-18 11:57:32+00:00
v13.13 = 2018-12-18 15:21:37+00:00
v14.14 = 2019-01-18 10:55:44+00:00
v15.15 = 2019-02-18 10:55:55+00:00
v16.16 = 2019-03-19 10:59:03+00:00
v17.17 = 2019-04-18 14:22:52+00:00
v18.18 = 2019-05-18 11:03:37+00:00
v19.19 = 2019-06-18 12:39:00+00:00
v20.20 = 2019-07-18 10:56:35+00:00
Current AIP Size = 21.42 MB
First published date = 2017-03-20
Data time coverage: 1998-01-22 to 2015-09-07
Accession: 0162173
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:17:20+00:00
Current AIP Size = 84.772 MB
First published date = 2017-03-20
Data time coverage: 2015-09-01 to 2016-12-16
Accession: 0162186
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-03-20 23:29:37+00:00
v1.2 = 2017-04-04 17:12:03+00:00
v2.3 = 2017-05-22 14:50:28+00:00
v3.4 = 2017-08-04 04:23:41+00:00
Current AIP Size = 944.24 MB
First published date = 2017-10-19
Data time coverage: 2017-09-14 to 2019-09-26
Accession: 0167435
Submitter: Northwest Association of Networked Ocean Observing Systems
v1.1 = 2017-10-19 07:16:06+00:00
v2.2 = 2017-11-16 10:16:12+00:00
v3.3 = 2018-01-16 10:16:14+00:00
v4.4 = 2018-10-17 10:16:20+00:00
v5.5 = 2018-11-17 10:26:49+00:00
v6.6 = 2018-12-17 13:53:12+00:00
v7.7 = 2019-02-17 11:29:46+00:00
v8.8 = 2019-04-17 10:43:21+00:00
v9.9 = 2019-07-17 10:17:39+00:00
v10.10 = 2019-08-17 10:17:51+00:00
v11.11 = 2019-09-17 10:17:45+00:00
v12.12 = 2019-10-17 17:25:04+00:00
v13.13 = 2020-03-17 13:10:05+00:00
Current AIP Size = 26.636 MB
First published date = 2017-03-20
Data time coverage: 2008-04-13 to 2017-10-01
Accession: 0162182
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = Saturn Estuary Station 01
v1.1 = 2017-03-20 23:27:01+00:00
v1.2 = 2017-04-04 17:11:56+00:00
v2.3 = 2017-06-17 11:11:02+00:00
v3.4 = 2017-08-04 02:04:45+00:00
v4.5 = 2017-10-16 10:50:44+00:00
v5.6 = 2021-02-19 19:16:23+00:00
v6.7 = 2021-03-17 12:46:22+00:00
Current AIP Size = 16699.616 MB
First published date = 2017-05-16
Data time coverage: 2000-05-24 to 2023-11-01
Accession: 0162621
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = Mott Basin
v1.1 = 2017-05-16 13:55:25+00:00
v2.2 = 2017-08-04 04:11:13+00:00
v3.3 = 2017-08-17 08:43:06+00:00
v4.4 = 2017-10-17 10:28:57+00:00
v5.5 = 2017-12-17 07:32:19+00:00
v6.6 = 2018-01-17 07:29:00+00:00
v7.7 = 2018-02-17 07:31:23+00:00
v8.8 = 2018-04-17 10:30:13+00:00
v9.9 = 2018-05-18 10:29:56+00:00
v10.10 = 2018-06-18 10:34:21+00:00
v11.11 = 2018-07-18 10:37:30+00:00
v12.12 = 2018-08-18 10:35:14+00:00
v13.13 = 2018-09-18 10:35:24+00:00
v14.14 = 2018-10-18 10:35:46+00:00
v15.15 = 2018-11-18 11:52:15+00:00
v16.16 = 2018-12-18 15:16:34+00:00
v17.17 = 2019-01-18 10:50:29+00:00
v18.18 = 2019-02-18 10:50:32+00:00
v19.19 = 2019-03-19 10:53:29+00:00
v20.20 = 2019-04-18 14:17:03+00:00
v21.21 = 2019-05-18 10:57:27+00:00
v22.22 = 2019-06-18 12:32:51+00:00
v23.23 = 2019-07-18 10:53:53+00:00
v24.24 = 2019-08-18 11:05:14+00:00
v25.25 = 2020-03-16 13:03:05+00:00
v26.26 = 2020-04-18 11:28:11+00:00
v27.27 = 2020-05-18 11:36:17+00:00
v28.28 = 2020-06-18 11:39:38+00:00
v29.29 = 2020-07-18 11:40:48+00:00
v30.30 = 2020-08-18 11:43:15+00:00
v31.31 = 2020-09-22 21:48:52+00:00
v32.32 = 2020-11-19 09:14:59+00:00
v33.33 = 2020-12-18 17:08:48+00:00
v34.34 = 2021-02-21 17:20:38+00:00
v35.35 = 2021-03-19 11:18:14+00:00
v36.36 = 2021-04-18 10:48:22+00:00
v37.37 = 2021-05-18 10:44:09+00:00
v38.38 = 2021-07-20 10:45:29+00:00
v39.39 = 2021-08-20 10:51:53+00:00
v40.40 = 2021-09-19 10:46:56+00:00
v41.41 = 2023-01-18 11:22:24+00:00
v42.42 = 2023-02-18 11:07:45+00:00
v43.43 = 2023-03-18 10:51:53+00:00
v44.44 = 2023-04-18 11:15:08+00:00
v45.45 = 2023-05-19 12:07:35+00:00
v46.46 = 2023-06-18 11:17:37+00:00
v47.47 = 2023-07-18 14:35:35+00:00
v48.48 = 2023-08-19 11:13:47+00:00
v49.49 = 2023-09-18 16:40:07+00:00
v50.50 = 2023-10-19 11:59:46+00:00
v51.51 = 2023-11-18 11:09:37+00:00
Current AIP Size = 4288.232 MB
First published date = 2017-03-20
Data time coverage: 2004-05-17 to 2023-01-23
Accession: 0162183
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = Offshore Buoy
v1.1 = 2017-03-20 23:28:55+00:00
v2.2 = 2017-08-04 02:06:32+00:00
v3.3 = 2017-08-16 10:17:50+00:00
v4.4 = 2017-10-17 07:17:54+00:00
v5.5 = 2017-12-16 10:18:17+00:00
v6.6 = 2018-02-16 10:17:59+00:00
v7.7 = 2018-05-17 10:18:12+00:00
v8.8 = 2018-07-17 10:20:21+00:00
v9.9 = 2018-08-17 10:22:19+00:00
v10.10 = 2018-09-17 10:22:12+00:00
v11.11 = 2018-10-17 10:23:29+00:00
v12.12 = 2018-11-17 10:36:25+00:00
v13.13 = 2018-12-17 14:03:19+00:00
v14.14 = 2019-01-17 10:30:39+00:00
v15.15 = 2019-02-17 11:38:30+00:00
v16.16 = 2019-06-17 10:33:01+00:00
v17.17 = 2019-07-17 10:32:11+00:00
v18.18 = 2019-08-17 10:36:34+00:00
v19.19 = 2019-09-17 10:31:18+00:00
v20.20 = 2019-10-17 17:38:34+00:00
v21.21 = 2019-11-17 11:24:52+00:00
v22.22 = 2019-12-17 15:05:00+00:00
v23.23 = 2020-04-17 10:51:01+00:00
v24.24 = 2021-08-19 22:49:42+00:00
v25.25 = 2021-09-17 13:30:16+00:00
v26.26 = 2023-01-17 10:58:32+00:00
v27.27 = 2023-02-17 11:02:01+00:00
v28.28 = 2023-03-17 10:30:07+00:00
Current AIP Size = 1171.812 MB
First published date = 2017-05-15
Data time coverage: 2008-04-19 to 2023-11-05
Accession: 0162617
Submitter: Northwest Association of Networked Ocean Observing Systems
Provider Platform Code = Saturn Estuary Station 03
v1.1 = 2017-05-15 20:15:43+00:00
v2.2 = 2017-08-04 04:01:17+00:00
v3.3 = 2017-08-16 11:09:03+00:00
v4.4 = 2017-10-17 08:12:09+00:00
v5.5 = 2017-12-16 11:34:44+00:00
v6.6 = 2018-01-16 11:11:12+00:00
v7.7 = 2018-02-16 11:14:29+00:00
v8.8 = 2018-04-16 21:21:20+00:00
v9.9 = 2018-05-17 11:13:32+00:00
v10.10 = 2018-06-17 11:23:58+00:00
v11.11 = 2018-07-17 11:37:10+00:00
v12.12 = 2018-08-17 11:34:34+00:00
v13.13 = 2018-09-17 11:31:10+00:00
v14.14 = 2018-10-17 11:37:21+00:00
v15.15 = 2018-11-17 12:47:55+00:00
v16.16 = 2018-12-17 15:26:58+00:00
v17.17 = 2019-01-17 12:20:20+00:00
v18.18 = 2019-02-17 13:06:22+00:00
v19.19 = 2019-03-18 14:20:33+00:00
v20.20 = 2019-04-17 12:35:52+00:00
v21.21 = 2019-05-17 16:20:22+00:00
v22.22 = 2019-06-17 12:27:40+00:00
v23.23 = 2019-07-17 12:37:50+00:00
v24.24 = 2019-08-17 12:49:31+00:00
v25.25 = 2019-12-17 16:25:53+00:00
v26.26 = 2020-01-22 14:36:07+00:00
v27.27 = 2020-03-17 16:47:35+00:00
v28.28 = 2020-04-17 13:53:41+00:00
v29.29 = 2020-05-17 18:18:47+00:00
v30.30 = 2020-06-18 01:15:53+00:00
v31.31 = 2020-07-17 13:55:22+00:00
v32.32 = 2020-08-17 15:11:35+00:00
v33.33 = 2020-09-22 14:43:06+00:00
v34.34 = 2020-10-19 13:19:48+00:00
v35.35 = 2020-11-18 02:30:20+00:00
v36.36 = 2020-12-17 17:22:07+00:00
v37.37 = 2021-02-20 01:21:58+00:00
v38.38 = 2021-03-18 11:48:02+00:00
v39.39 = 2021-04-17 11:57:53+00:00
v40.40 = 2021-05-17 11:53:36+00:00
v41.41 = 2021-07-19 11:47:53+00:00
v42.42 = 2021-08-19 23:48:00+00:00
v43.43 = 2021-09-18 11:46:48+00:00
v44.44 = 2023-01-17 12:59:17+00:00
v45.45 = 2023-02-17 12:28:16+00:00
v46.46 = 2023-03-17 12:23:43+00:00
v47.47 = 2023-04-17 12:36:02+00:00
v48.48 = 2023-05-18 12:48:59+00:00
v49.49 = 2023-06-17 12:25:06+00:00
v50.50 = 2023-07-17 17:55:23+00:00
v51.51 = 2023-08-18 13:14:13+00:00
v52.52 = 2023-09-17 14:18:17+00:00
v53.53 = 2023-10-17 14:20:05+00:00
v54.54 = 2023-11-17 12:32:49+00:00
Current AIP Size = 14532.184 MB
Create a timeseries plot of data coverage#
Now that we have a DataFrame with all the information we’re interested in, lets make a time coverage plot for all the AIP’s at NCEI.
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
ypos = range(len(df))
fig, ax = plt.subplots(figsize=(15, 12))
# Plot the data
ax.barh(
ypos,
mdates.date2num(df["data_end_date"]) - mdates.date2num(df["data_start_date"]),
left=mdates.date2num(df["data_start_date"]),
height=0.5,
align="center",
)
xlim = (
mdates.date2num(df["data_start_date"].min() - pd.Timedelta(30, "d")),
mdates.date2num(df["data_end_date"].max() + pd.Timedelta(30, "d")),
)
ax.set_xlim(xlim)
ax.set(yticks=np.arange(0, len(df)))
ax.tick_params(which="both", direction="out")
ax.set_ylabel("NCEI Accession Number")
ax.set_yticklabels(df["NCEI_accession_number"])
ax.set_title("NCEI archive package time coverage")
ax.xaxis_date()
ax.set_xlabel("Date")
ax.grid(axis="x", linestyle="--")
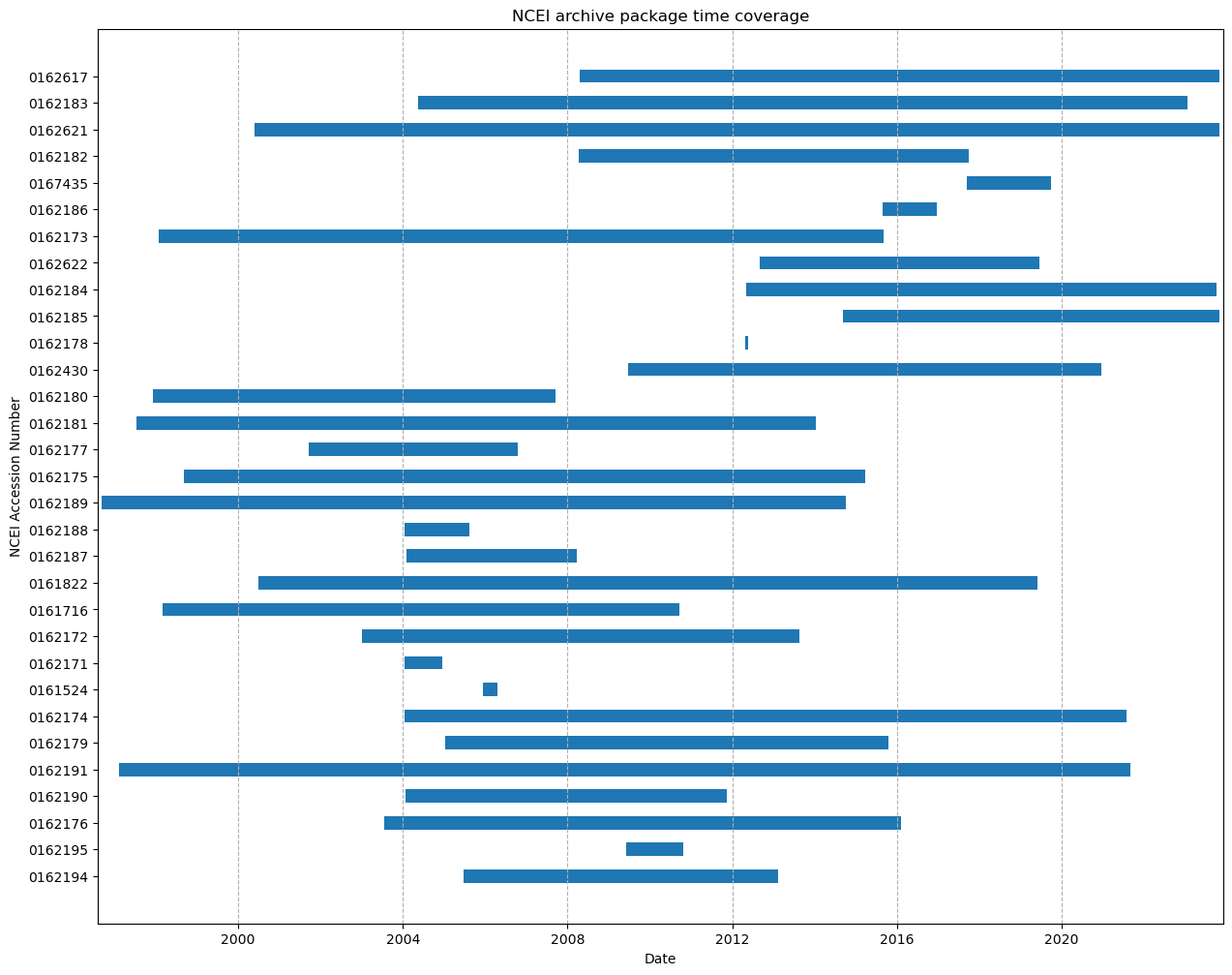
This procedure has been developed as an example of how to use NCEI’s geoportal REST API’s to collect information about packages that have been archived at NCEI. The intention is to provide some guidance and ways to collect this information without having to request it directly from NCEI. There are a significant amount of metadata elements which NCEI makes available through their ISO metadata records. Therefore, anyone interested in collecting other information from the records at NCEI should have a look at the ISO metadata records and determine which items are of interest to their community. Then, update the example code provided to collect that information.
Author: Mathew Biddle