Reading and writting zarr files with xarray#
Created: 2023-03-20
Updated: 2026-02-02
The zarr format is a file storage based specification for chunked, compressed, N-dimensional arrays. The format is based on an open-source specification and its main goal is to make cloud data read/write a bit easier and more effective.
The main propblems in data storage are:
Read/write data that is larger than memory
Being able to parallelize computations
Reduce the I/O botteneck
Compression
Speed
One solution is to use a chunked* parallel computing framework and a chunked parallel storage library. Zarr helps us with the latter.
In this example we will load an ocean model data, stored as netCDF and served via THREDDS, subset it and save as zarr. Let’s start by saving a single time step for the surface layer temperature and salinity.
* Many data formats can take advantage of storing the data in chunks for faster access, the zarr approach is different in that each chunk is a different object in cloud storage, making them better for parallel access. The chunks can be compressed to reduce their size and improve cloud performance even further. Zarr has a nice tutorial on how to balance chunk size for performance. Check it out: https://zarr.readthedocs.io/en/stable/user-guide/performance/.
import xarray as xr
url = "https://tds.marine.rutgers.edu/thredds/dodsC/roms/doppio/2017_da/avg/Averages_Best_Excluding_Day1"
ds = xr.open_dataset(url)
time_slice = {"time1": "2022-06-06"}
surface = {"s_rho": -1}
ds = ds[["temp", "salt"]].sel(time_slice).isel(surface)
ds
<xarray.Dataset> Size: 821kB
Dimensions: (time1: 1, eta_rho: 106, xi_rho: 242)
Coordinates:
* time1 (time1) datetime64[ns] 8B 2022-06-06T12:00:00
time1_run (time1) datetime64[ns] 8B ...
lon_rho (eta_rho, xi_rho) float64 205kB ...
lat_rho (eta_rho, xi_rho) float64 205kB ...
s_rho float64 8B -0.0125
Dimensions without coordinates: eta_rho, xi_rho
Data variables:
temp (time1, eta_rho, xi_rho) float64 205kB ...
salt (time1, eta_rho, xi_rho) float64 205kB ...
Attributes: (12/46)
file: doppio_avg_7309_0001.nc
format: netCDF-4/HDF5 file
Conventions: CF-1.4, SGRID-0.3
type: ROMS/TOMS nonlinear model averages file
title: ROMS doppio Real-Time Operational PSAS F...
var_info: ../Data/varinfo1040t_daily.dat
... ...
frc_file_07: ../Data/Winds_ncepnam_3hourly_MAB_and_Go...
cdm_data_type: GRID
featureType: GRID
location: Proto fmrc:doppio_2017_da_avg
summary: doppio
DODS_EXTRA.Unlimited_Dimension: ocean_timeimport humanize
humanize.naturalsize(ds.nbytes)
'820.9 kB'
It is a small subset but it is enough to ilustrate zarr’s compression options.
Now let’s choose a compression level and save it as zarr.
from zarr.codecs import BloscCodec
compressor = BloscCodec(clevel=2, shuffle="bitshuffle")
fname = "doppio/doppio_compressed.zarr"
ds.to_zarr(
fname,
mode="w",
safe_chunks=True,
consolidated=False,
encoding={var: {"compressors": compressor} for var in ds.variables},
);
!tree doppio/*zarr
!du -h doppio/*zarr
doppio/doppio_compressed.zarr
├── lat_rho
│ ├── c
│ │ └── 0
│ │ └── 0
│ └── zarr.json
├── lon_rho
│ ├── c
│ │ └── 0
│ │ └── 0
│ └── zarr.json
├── salt
│ ├── c
│ │ └── 0
│ │ └── 0
│ │ └── 0
│ └── zarr.json
├── s_rho
│ ├── c
│ └── zarr.json
├── temp
│ ├── c
│ │ └── 0
│ │ └── 0
│ │ └── 0
│ └── zarr.json
├── time1
│ └── zarr.json
├── time1_run
│ └── zarr.json
└── zarr.json
18 directories, 13 files
136K doppio/doppio_compressed.zarr/salt/c/0/0
140K doppio/doppio_compressed.zarr/salt/c/0
144K doppio/doppio_compressed.zarr/salt/c
152K doppio/doppio_compressed.zarr/salt
8.0K doppio/doppio_compressed.zarr/time1_run
160K doppio/doppio_compressed.zarr/lat_rho/c/0
164K doppio/doppio_compressed.zarr/lat_rho/c
172K doppio/doppio_compressed.zarr/lat_rho
140K doppio/doppio_compressed.zarr/temp/c/0/0
144K doppio/doppio_compressed.zarr/temp/c/0
148K doppio/doppio_compressed.zarr/temp/c
156K doppio/doppio_compressed.zarr/temp
148K doppio/doppio_compressed.zarr/lon_rho/c/0
152K doppio/doppio_compressed.zarr/lon_rho/c
160K doppio/doppio_compressed.zarr/lon_rho
12K doppio/doppio_compressed.zarr/s_rho
8.0K doppio/doppio_compressed.zarr/time1
676K doppio/doppio_compressed.zarr
The first thing to observe is that the zarr format is a directory based storage. That structure should be familiar for HDF5 users. However, instead of being a filesystem inside a filesystem, zarr is layed out directly on the disk filesystem.
Each variable and coordinate has its own directory and the data chunks are stored in subdirectories. For more information check this awesome presentation from one of zarr authors.
Note that the stored size is quite smaller too! We went from 820.9 kB to 676 kB. Zarr has many modern compression oprions as plugins, including some bitinformation based methods.
The data attributes, groups, and metdata are stored in the .zattrs, .zgroup, and .zmetadata. They are plain text JSON files and easy to parse:
import json
with open("doppio/doppio_compressed.zarr/zarr.json") as f:
zmetadata = json.loads(f.read())
zmetadata
{'attributes': {'file': 'doppio_avg_7309_0001.nc',
'format': 'netCDF-4/HDF5 file',
'Conventions': 'CF-1.4, SGRID-0.3',
'type': 'ROMS/TOMS nonlinear model averages file',
'title': 'ROMS doppio Real-Time Operational PSAS Forecast System Version 1 FMRC Averages',
'var_info': '../Data/varinfo1040t_daily.dat',
'rst_file': 'doppio_rst_7309.nc',
'his_base': 'doppio_his_7309',
'avg_base': 'doppio_avg_7309',
'flt_file': 'doppio_flt_7309.nc',
'grd_file': '/home/om/roms/doppio/7km/grid_doppio_JJA_v13.nc',
'ini_file': 'doppio_ini_7309.nc',
'tide_file': '/home/om/roms/doppio/7km/doppio_tide_7km.nc',
'frc_file_01': '../PSAS/doppio_flx_7309_outer2.nc',
'clm_file_01': '../Data/doppio_clm.nc',
'nud_file': '/home/om/roms/doppio/7km/doppio_nudgcoef_7km_1500-2000_GS.nc',
'script_file': 'nl_ocean_doppio.in',
'fpos_file': 'floats.in',
'NLM_TADV': '\nADVECTION: HORIZONTAL VERTICAL \ntemp: Akima4 Akima4 \nsalt: Akima4 Akima4',
'NLM_LBC': '\nEDGE: WEST SOUTH EAST NORTH \nzeta: Cha Cha Cha Clo \nubar: Fla Fla Fla Clo \nvbar: Fla Fla Fla Clo \nu: RadNud RadNud RadNud Clo \nv: RadNud RadNud RadNud Clo \ntemp: Rad Rad Rad Clo \nsalt: Rad Rad Rad Clo \ntke: Gra Gra Gra Clo',
'svn_url': 'https://www.myroms.org/svn/src/trunk',
'svn_rev': '1040',
'code_dir': '/home/julia/ROMS/doppio/svn1040t',
'header_dir': '/home/julia/ROMS/doppio/Compile/fwd',
'header_file': 'doppio.h',
'os': 'Linux',
'cpu': 'x86_64',
'compiler_system': 'ifort',
'compiler_command': '/opt/sw/apps/intel-2021_8/openmpi/4.1.5/bin/mpif90',
'compiler_flags': '-fp-model precise -heap-arrays -ip -O3 -traceback -check uninit',
'tiling': '004x004',
'history': 'ROMS/TOMS, Version 3.9, Thursday - January 8, 2026 - 4:23:17 AM ;\nFMRC Best_Excluding_Day1 Dataset',
'ana_file': 'ROMS/Functionals/ana_btflux.h',
'CPP_options': 'DOPPIO, ADD_FSOBC, ADD_M2OBC, ANA_BSFLUX, ANA_BTFLUX, ASSUMED_SHAPE, ATM_PRESS, AVERAGES, !BOUNDARY_A !COLLECT_ALL..., CHARNOK, CRAIG_BANNER, CURVGRID, DEFLATE, DJ_GRADPS, DOUBLE_PRECISION, FLOATS, FORWARD_WRITE, GLS_MIXING, HDF5, KANTHA_CLAYSON, MASKING, MIX_GEO_TS, MIX_S_UV, MPI, NONLINEAR, NONLIN_EOS, NO_LBC_ATT, N2S2_HORAVG, OUT_DOUBLE, POWER_LAW, PROFILE, K_GSCHEME, REDUCE_ALLREDUCE, !RST_SINGLE, SALINITY, SOLAR_SOURCE, SOLVE3D, SSH_TIDES, TS_DIF2, UV_ADV, UV_COR, UV_U3HADVECTION, UV_C4VADVECTION, UV_QDRAG, UV_TIDES, UV_VIS2, VAR_RHO_2D, WIND_MINUS_CURRENT',
'_CoordSysBuilder': 'ucar.nc2.dataset.conv.CF1Convention',
'frc_file_02': '../Data/Pair_ncepnam_3hourly_MAB_and_GoM.nc',
'frc_file_03': '../Data/Qair_ncepnam_3hourly_MAB_and_GoM.nc',
'frc_file_04': '../Data/rain_ncepnam_3hourly_MAB_and_GoM.nc',
'frc_file_05': '../Data/swrad_daily_ncepnam_3hourly_MAB_and_GoM.nc',
'frc_file_06': '../Data/Tair_ncepnam_3hourly_MAB_and_GoM.nc',
'frc_file_07': '../Data/Winds_ncepnam_3hourly_MAB_and_GoM.nc',
'cdm_data_type': 'GRID',
'featureType': 'GRID',
'location': 'Proto fmrc:doppio_2017_da_avg',
'summary': 'doppio',
'DODS_EXTRA.Unlimited_Dimension': 'ocean_time'},
'zarr_format': 3,
'node_type': 'group'}
New let’s read back the data to check if we can roundtrip it back to the original dataset.
subset = xr.open_zarr(fname, consolidated=False)
subset
<xarray.Dataset> Size: 821kB
Dimensions: (time1: 1, eta_rho: 106, xi_rho: 242)
Coordinates:
* time1 (time1) datetime64[ns] 8B 2022-06-06T12:00:00
time1_run (time1) datetime64[ns] 8B ...
lat_rho (eta_rho, xi_rho) float64 205kB ...
lon_rho (eta_rho, xi_rho) float64 205kB ...
s_rho float64 8B ...
Dimensions without coordinates: eta_rho, xi_rho
Data variables:
salt (time1, eta_rho, xi_rho) float64 205kB ...
temp (time1, eta_rho, xi_rho) float64 205kB ...
Attributes: (12/46)
file: doppio_avg_7309_0001.nc
format: netCDF-4/HDF5 file
Conventions: CF-1.4, SGRID-0.3
type: ROMS/TOMS nonlinear model averages file
title: ROMS doppio Real-Time Operational PSAS F...
var_info: ../Data/varinfo1040t_daily.dat
... ...
frc_file_07: ../Data/Winds_ncepnam_3hourly_MAB_and_Go...
cdm_data_type: GRID
featureType: GRID
location: Proto fmrc:doppio_2017_da_avg
summary: doppio
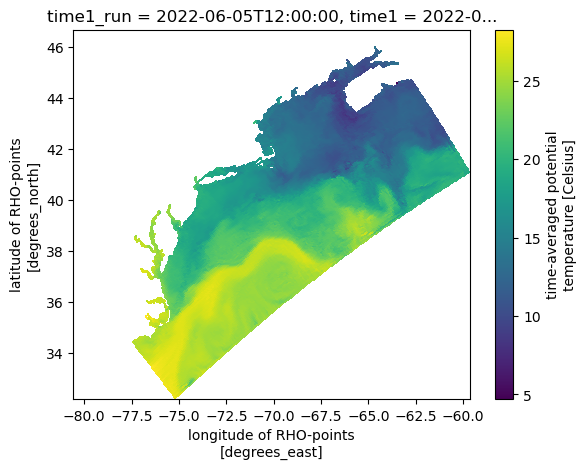
DODS_EXTRA.Unlimited_Dimension: ocean_timeAnd a quick plot to check the data.
subset["temp"].compute().squeeze().plot(x="lon_rho", y="lat_rho");
What is the current workflow and what are the altearnatives? Most ocean data are stored as modern netCDF files that are, under the hood HDF5 files with more strict metadata stuture. HDF5 has some limitations like,
no thread-based parallelism
cannot do parallel writes with compression
no support for could object stores
However, for most workflows what really matters is the chunking, not the data format. Leaving the parallelism, compression, and cloud support to be built on top of it with dask, numcodecs, and fsspec, respectively. That raises the question: Should one convert all the existing data to zarr? Luckily no! We can adopt a more inexpensive workflow and kerchunk to create virtual cloud-optimized CF-compliant datasets that access files in any format using the Zarr library.
We can write the data in whatever format we need (maybe you are NASA and require HDF5, maybe you have R users who like netcdf, or want to use a visualization tool that only reads geotiff), then rechunk the data to best support the expected use cases.